A couple weeks ago Jason Kottke posted a complaint about Technorati. Its search results are slow, non-comprehensive, of mediocre relevance, and can’t even manage one nine of reliability. Technorati’s competitors all have the second problem and have or will likely have the others as they grow.
Kevin Burton would prefer blog search to aim lower:
I’d rather have a Technorati that was fast and always worked even if that meant only indexing 1M blogs. Even 500k blogs as long as they are the top 500k blogs.
Sounds like a reasonable tradeoff, but it’s completely unacceptable. What if Google had decided to index only 100M web pages in order to stay fast and reliable? Google would no longer exist. (Also pretend you read something about the long tail of the blogosphere here.)
Only one of thirty trackbacks to Kottke’s post states the obvious:
When I first encountered RSS search engines a few years ago while at Yahoo! I wondered how they could survive. The difficult part of RSS search isn’t the RSS, it’s the search. Search is hard. For Google or Yahoo!, adding RSS to search is trivial. It’s just another data source. And yes, setting up a ping server is different from crawling links, but not any harder and once you get the content, it’s indexed in basically the same fashion. But for Technorati, adding world class relevence, freshness, comprehensiveness and scalability to RSS is an almost insurmountable effort.
(Possibly two, but this one is mostly in Chinese. Google’s beta Chinese-English translation says in part “very many people anticipates Google/Yahoo can provide the even better function.”)
I hope Technorati, PubSub, IceRocket, BlogPulse, Feedster, et al do well, but my expectation is for one or more of Google, Yahoo!, or Microsoft to introduce a superior blog search service and eventually for blog search to be an anachronism, subsumed by web search (though I want every site and page to have a feed, so web search should become a bit more like blog search). I want to comprehensively track a webversation starting at any URL, and that requires something that can pass for a comprehensive web index.
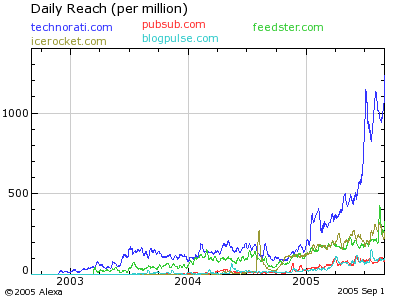
Here’s a graph from Alexa showing the “reach” of Technorati and (clearly less popular) competitors:
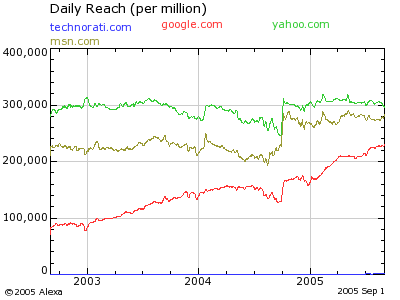
For comparison Alexa says that Google is used by (only?) a little over one in five browsers a day (over 200,000 per million):
Good blog post.
I wasn’t saying that they should only aggegate few blogs forever .. just until they get to the point where they can scale better. It’s more important to have happy customers than no customers.
Using Alexa numbers to compare blog search services is, unfortunately, of very limited utility. The problem is especially clear when you include PubSub in the mix. The vast majority of our users get their data from us by either polling RSS/Atom feeds or by using our Jabber/XMPP based “PubSub Sidebar” or the Gush Reader. There isn’t much you can do on our website except create/delete/modify a subscription. Thus, there isn’t much activity for Alexa to watch. Frankly, we’ve designed our system to minimize unnecessary web traffic. Thus, our Alexa numbers will always be lower than you might expect. We could easily increase our Alexa numbers simply by forcing users to click on more pages or force them to come back to the web site more frequently — but that would only serve our interests in helping to confuse folk who attempt to use Alexa data against us. Doing what it takes to get better Alexa numbers would NOT be in the interests of our users. Thus, we won’t do it.
bob wyman
Kevin: Yeah, maybe they could do some very short term feed triage, but that wouldn’t help them scale better (which is a requirement, or they will have no customers in the not too distant future) and would piss off many customers–bloggers on long tail.
Bob: Good point. I imagine a graph of actual use would look something like the alexa graph above, but with pubsub shifted upward by some factor. Still, it is clear that Technorati has had a higher growth rate this year, with “reach” increasing something like 5x, vs. something like 2-3x for the others graphed.
[…] The second reason I link to Wikipedia preferentially2 is that Wikipedia article URLs conveniently serve as “tags, as specified by the rel=”tag” microformat. If Technorati and its competitors happen to index this blog this month, it will show up in their tag-based searches, the names of the various Wikipedia articles I’ve linked to serving to name tags. I’ve never been enthusiastic about the overall utility of author applied tags, but I figure linking to Wikipedia is not as bad as linking to a tagreggator. […]
[…] I’d been meaning to put together an Alexa graph generating utility for months (well, one more accessible than URL editing, which I’ve always used, e.g., the graphs at the bottom of a post on blog search) and I finally got started last night. […]
[…] I should have said Google web search above. As Chris Masse points out in a comment below, blog search still stinks and so far Google and Yahoo! blog search do not improve the state of the art, contrary to my expectations. […]
[…] complained before here that blog search stinks and isn’t getting better. Now I know why — in addition to blog search being a difficult […]