
By Falkvinge on Infopolicy columnist Zacqary Adam Green (also creator of the excellent Your Face Is A Saxophone cartoon).
Already used in my presentation today at the Linux Collaboration Summit, (pdf, odp, slideshare).
By Falkvinge on Infopolicy columnist Zacqary Adam Green (also creator of the excellent Your Face Is A Saxophone cartoon).
Already used in my presentation today at the Linux Collaboration Summit, (pdf, odp, slideshare).
 At the FSF’s annual conference last year I pledged to donate 100BTC to the FSF, and did so on April 6. I bought about 121.95 bitcoins, for a price of about US$4.92/BTC (made easier thanks to Greg Maxwell’s vouching for me on #bitcoin-otc; thanks!) and haven’t given any thought to the remainder till today. As I write this the USD/BTC price is approximately US$105.40/BTC.
At the FSF’s annual conference last year I pledged to donate 100BTC to the FSF, and did so on April 6. I bought about 121.95 bitcoins, for a price of about US$4.92/BTC (made easier thanks to Greg Maxwell’s vouching for me on #bitcoin-otc; thanks!) and haven’t given any thought to the remainder till today. As I write this the USD/BTC price is approximately US$105.40/BTC.
((21.95*105.40)-(121.95*4.92))/(121.95*4.92) = 2.8559218925522587
You too can invest! How to buy bitcoins. Donate to the FSF and other “notable” bitcoin-accepting organizations, many of which I endorse. Results not typical.
…
For the long term, I’m sticking with my prediction of almost two years ago that “governments and any other entity with a large measure of control over how it can demand payment will launch their own cryptocurrencies, seeking endowments for themselves much as Bitcoin’s inventor and early adopters may have gained.”
I have a similar long-term prediction for seasteading: “if seasteads did meet engineering and economic challenges, they would merely be used by states to stake exclusive claims to all of the planet’s surface.”
Open formats and open standards are excellent causes, but without free/open source software implementations and widespread adoption thereof, the causes are uphill battles, at best. So I’m appalled that the Document Freedom Day (which is today, March 27) website information and suggested actions are merely conceptual.
Let’s fix that, here’s the deal. Download, try, become an expert:
LibreOffice. If in 2013 you’re still using Microsoft Office, you’re either in an organization/industry with extreme lock-in through custom business automation or similar that is built exclusively on Microsoft tools, or you’re actively contributing to the destruction of freedom and equality in the world. If you’ve never tried LibreOffice, or if you’ve tried one of its predecessors (OpenOffice) more than a year ago, try LibreOffice (again) now. It’s excellent, including at reading and writing non-free document formats, a necessity for adoption. But most of the value in software is not inherent, rather in many people using and knowing the software. Network effects rule, and you can make a huge difference! If you can’t be bothered, make up for it with a large donation to The Document Foundation, LibreOffice’s nonprofit organization.
As the DFD website explains, document freedom isn’t just about word processor and spreadsheet documents, or even just about storage formats, but any format used to store or transmit data. Thus I put Jitsi as the second most important application to use in order to realize document freedom. It implements open standards such as XMPP and SIP to provide all of the functionality of Skype, which is completely proprietary in its formats and implementation, willing to work with oppressive governments, and increasingly castigated as bloatware or even malware by people who don’t care much about freedom. Jitsi recently released 2.0. If in the unlikely event you’ve tried it before, it’s definitely worth another look.
Probably everyone knows about Firefox, but not everyone uses it, and it does have the best support for open formats of the top browsers. Also, Firefox has progressed very nicely the last years.

DFD has missed an opportunity to promote the realization of document freedom, but that would be good in addition to, not in place of their existing messages. Direct use of free software that implements open standards is incredibly powerful, but not the only way to make progress, and despite my mini-rant above The free software movement attaches too much political significance to personal practice. People should demand their governments and other institutions adopt open standards and free software, even if people cannot do so as individuals, just as people should generally demand adoption of good policy even if they cannot personally live wholly as if good policy were already in place.
DFD does a reasonable job of raising awareness of good policy. I strongly encourage doing a bit to realize document freedom today, but sharing a link to documentfreedom.org on your social networks helps too. Just a little bit, but what can you expect from clicktivism?
…
I expect pro-free/open clicktivism to promote the realization of freedom!
I have similar complaints about Defective By Design campaigns. Speaking of which, their No DRM in HTML5 campaign is highly pertinent to DFD!
Putatively “open” advocates and organizations sending around .docx files and such, above mini-rant applies especially to you.
April (a French free software organization) has some nice posters explaining open formats.
 Since March 15 a year ago free software developer and colleague Bassel Khartibil has been imprisoned in Syria. The #FREEBASSEL campaign says “We will not stop campaigning for him until we see him as a free global citizen once again.”
Since March 15 a year ago free software developer and colleague Bassel Khartibil has been imprisoned in Syria. The #FREEBASSEL campaign says “We will not stop campaigning for him until we see him as a free global citizen once again.”
Sign a petition on freebassel.org and participate in events (eg, one in SF) and take other action especially on March 15, Free Bassel Day.
As an American, I am somewhat uncomfortable calling for the Syrian regime to do anything, without at a minimum apologizing for the terror the American regime has for decades unleashed on the region, and continues to do so. I apologize, vow to redouble my efforts to stop my jurisdiction’s murdering and torturing ways, to obtain justice for all who bring such to light, call on all to do the same … and demand freedom for Bassel Khartibil.
As a global citizen, I demand to see Bassel Khartibil as a free global citizen once again. FREEBASSEL!
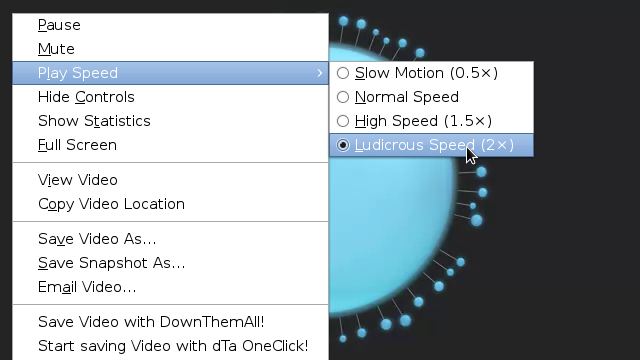
Listening or viewing non-fiction/non-art (eg lectures, presentations) at realtime speed is tiresome. I’ve long used rbpitch (but more control than I need or want) or VLC’s built-in playback speed menu (but mildly annoyed by “Faster” and “Faster (fine)”; would prefer to see exact rate) and am grateful that most videos on YouTube now feature a playback UI that allows playback at 1.5x or 2x speed. The UI I like the best so far is Coursera’s, which very prominently facilitates switching to 1.5x or 2x speed as well as up and down by 0.25x increments, and saving a per-course playback rate preference.
HTML5 audio and video unadorned with a customized UI (latter is what I’m seeing at YouTube and Coursera) is not everywhere, but it’s becoming more common, and probably will continue to as adding video or audio content to a page is now as easy as adding a non-moving image, at least if default playback UI in browsers is featureful. I hope for this outcome, as hosting site customizations often obscure functionality, eg by taking over the context menu (could browsers provide a way for users to always obtain the default context menu on demand?).
Last month I submitted a feature request for Firefox to support changing playback speed in the default UI, and I’m really happy with the response. The feature is now available in nightly builds (which are non-scary; I’ve run nothing else for a long time; they just auto-update approximately daily, include all the latest improvements, and in my experience are as stable as releases, which these days means very stable) and should be available in a general release in approximately 18-24 weeks. You can test the feature on the page the screenshot above is from; note it will work on some of the videos, but for others the host has hijacked the context menu. Or something that really benefits from 2x speed (which is not at all ludicrous; it’s my normal speed for lectures and presentations that I’m paying close attention to).
Even better, the request was almost immediately triaged as a “[good first bug]” and assigned a mentor (Jared Wein) who provided some strong hints as to what would need to be done, so strong that I was motivated to set up a Firefox development environment (mostly well documented and easy; the only problem I had was figuring out which of the various test harnesses available to test Firefox in various ways was the right one to run my tests) and get an unpolished version of the feature working for myself. I stopped when darkowlzz indicated interest, and it was fun to watch darkolzz, Jared, and a couple others interact over the next few weeks to develop a production-ready version of the feature. Thank you Jared and darkowlzz! (While looking for links for each, I noticed Jared posted about the new feature, check that out!)
Kodus also to Mozilla for having a solid easy bug and mentoring process in place. I doubt I’ll ever contribute anything non-trivial, but the next time I get around to making a simple feature request, I’ll be much more likely to think about attempting a solution myself. It’s fairly common now for projects have at least tag easy bugs; OpenHatch aggregates many of those. I’m not sure how common mentored bugs are.
I also lucked out in that support for setting playback rate from javascript had recently been implemented in Firefox. Also see documentation for the javascript API for HTML5 media elements and what browser versions implement each.
Back to playback rate, I’d really like to see anything that provides an interface to playing timed media to facilitate changing playback rate. Anything else is a huge waste of users’ time and attention. A user preference for playback rate (which might be as simple as always using the last rate, or as complicated as a user-specified calculation based on source and other metadata) would be a nice bonus.
The Obama administration:
has directed Federal agencies with more than $100M in R&D expenditures to develop plans to make the published results of federally funded research freely available to the public within one year of publication and requiring researchers to better account for and manage the digital data resulting from federally funded scientific research
A similar policy has been in place for NIH funded research for several years, and more are in the works around the world.
Peter Suber, as far as I can tell the preeminent chronicler of the Open Access (OA) movement, and one of its primary activists, seems to have the go-to summary post.
Congratulations and thanks to all OA activists. I want to take this particular milestone in order to make some exaggerated contrasts between OA and free/libre/open source software (FLOSS). I won’t bother with cultural, educational, and other variants, but assume they’re somewhere between and lagging overall.
If you’ve followed either movement you can think of exceptions. I suspect the above generalizations are correct as such, but tell me I’m wrong.
Career arrangements are an obvious motivator of some of these differences: science more institutional and tracked, less varied relative to programming. Thus where acting on individual ethics alone with regard to publishing is often characterized as suicidal for a scientist, it is welcome, but not extraordinary nor a cause for concern for a programmer. At the same time, FLOSS people might overestimate the effectiveness of individual choices, merely because they are relatively easy to make and expressive.
One can imagine a universe in which facts are different enough that the characteristics of movements for something like open research and software are reversed, eg no giant institutions and centralized funding, but radical individual ethics for science, dominance of amazing mainframes and push for software escrow for programming. Maybe our universe isn’t that bad, eh?
I do not claim one approach is superior to the other. Indeed I think there’s plenty each can learn from the other. Tip-of-the-iceberg examples: I appreciate those making FLOSS-like demands of OA, think those working on government and institutional policy in FLOSS should be appreciated much more, and the global ethical dimension of FLOSS, in particular with regard to A2K-like equality implications, badly needs to be articulated.
Beyond much needed learning and copying of strategies, some of those involved in OA and FLOSS (and that in between and lagging) might better appreciate each others’ objectives, their commonalities, and actively collaborate. All ignore computational dominance of everything at their peril, and software people self-limit, self-marginalize, even self-refute by limiting their ethics and action to software.
“Commoning the noosphere” sounds anachronistic, but is yet to be, and I suspect involves much more than a superset of OA and FLOSS strategy and critique.
I used to privately poke fun at the Open Knowledge Foundation for what seemed like a never-ending stream of half-baked projects (and domains, websites, lists, etc). I was wrong.
(I have also criticized OKF’s creation of a database-specific copyleft license, but recognize its existence is mostly Creative Commons’ fault, just as I criticize some of Creative Commons’ licenses but recognize that their existence is mostly due to a lack of vision on the part of free software activists.)
Some of those projects have become truly impressive (e.g. the Public Domain Review and CKAN, the latter being a “data portal” deployed by numerous governments in direct competition with proprietary “solutions”; hopefully my local government will eventually adopt the instance OpenOakland has set up). Some projects once deemed important seem relatively stagnant, but were way ahead of their time, if only because the non-software free/open universe painfully lags software (e.g. KnowledgeForge). I haven’t kept track of most OKF projects, but whichever ones haven’t succeeded wildly don’t seem to have caused overall problems.
Also, in the past couple years, OKF has sprouted local groups around the world.
Why has the OKF succeeded, despite what seemed to me for a time chaotic behavior?
OKF is far from perfect (in particular I think it is too detached from free/open source software, to the detriment of open data and reducing my confidence it will continue to say on a fully Open course — through action and recruitment — one of their more ironic practices at this moment is the Google map at the top of their local groups page [Update: already fixed, see comments]). But it is an excellent organization, at this point probably the single best connection to all things Open, irrespective of field or geography.
Check them out online, join or start a local group, and if you’re interested in the minutiae of of whether particular licenses for intended-to-be-open culture/data/education/government/research works are actually open, help me out with OKF’s OpenDefinition.org project.
Points 1-4 of my year-ago post, Which counterfactual public domain day? hold up well, but number 5 could be improved: it concerns optimal copyright term, which is a rather narrow issue, and viewed from an unhealthy side.
Instead, consider that in common language, and presumably to most people, “in the public domain” means something like “revealed to the public” or “not secret”, as the first definition currently presented by Google reflects:
pub·lic do·main
noun
public domains, plural
- The state of belonging or being available to the public as a whole
- Not subject to copyright
- the photograph had been in the public domain for 15 years
- public-domain software
- Public land
- a grazing permit on public domain
It’s not clear how Google’s computers selected those definitions, but they did a good job: “intellectual property” focused definitions seem to have largely crowded out the common usage in written down definitions.
The common “available to the public as a whole” understanding reflects why I have been more recently careful to stress that copyright policy is a small part of information policy and that reducing copyright restrictions (anti-sharing regulation), all the way to abolition, are in this broader context moderate reforms — more thoroughgoing reform would have to consider pro-sharing regulation (as I’ve said many times, broadly construed; choose the mechanisms that fit your ideological commitments) — requiring information revelation, eg of computer program source code.
People curating and promoting works not subject to copyrestriction, information preservationists, leakers, transparency activists, and many others provide various sorts of pro-public-domain regulation. But I especially want to recognize enforcers of copyleft regulation as benefiting (though problematically) the commonly understood public domain, and in the most important field (computation is suffusing everything, security through obscurity isn’t, etc).
…
Happy Public Domains Day. I offer a cornucopia of vague jokes, indeed.

Last week I attended CODATA 2012 in Taipei, the biannual conference of the Committee on Data for Science and Technology. I struggled a bit with deciding to go — I am not a “data scientist†nor a scientist and while I know a fair amount about some of the technical and policy issues for data management, specific application to science has never been my expertise, all away from my current focus, and I’m skeptical of travel.
I finally went in order to see through a session on mass collaboration data projects and policies that I developed with Tyng-Ruey Chuang and Shun-Ling Chen. A mere rationalization as they didn’t really need my presence, but I enjoyed the conference and trip anyway.
My favorite moments from the panel:
My slides from the panel (odp, pdf, slideshare) and from an open data workshop following the conference (odp, pdf, slideshare).
Tracey Lauriault summarized the mass collaboration panel (all of it, check out the parts I do not mention), including:
Mike Linksvayer, was provocative in stating that copyright makes us stupider and is stupid and that it should be abolished all together. I argued that for traditional knowledge where people are seriously marginalized and where TK is exploited, copyright might be the only way to protect themselves.
I’m pretty sure I only claimed that including copyright in one’s thinking about any topic, e.g., data policy, effectively makes one’s thinking about that topic more muddled and indeed stupid. I’ve posted about this before but consider a post enumerating the ways copyright makes people stupid individually and collectively forthcoming.
I didn’t say anything about abolishing copyright, but I’m happy for that conclusion to be drawn — I’d be even happier for the conclusion to be drawn that abolition is a moderate reform and boring (in no-brainer and non-interesting senses) among the possibilities for information and innovation policies — indeed, copyright has made society stupid about these broader issues. I sort of make these points in my future of copyright piece that Lauriault linked to, but will eventually address them directly.
Also, Traditional Knowledge, about which I’ve never posted unless you count my claim that malgovernance of the information commons is ancient, for example cult secrets (mentioned in first paragraph of previous link), though I didn’t have contemporary indigenous peoples in mind, and TK covers a wide range of issues. Indeed, my instinct is to divide these between issues where traditional communities are being excluded from their heritage (e.g., plant patents, institutionally-held data and items, perhaps copyrestricted cultural works building on traditional culture) and where they would like to have a collective right to exclude information from the global public domain.
…
The theme of CODATA 2012 was “Open Data and Information for a Changing Planet†and the closing plenary appropriately aimed to place the entire conference in that context, and question its impact and followup. That included the inevitable asking whether anyone would notice. At the beginning of the conference attendees were excitedly encouraged to tweet, and if I understood correctly, there were some conference staff to be dedicated to helping people tweet. As usual, I find this sort of exhortation and dedication of resources to social media scary. But what about journalists? How can we make the media care?
Fortunately for (future) CODATA and other science and data related events, there’s a great answer (usually there isn’t one), but one I didn’t hear mentioned at all outside of my own presentation: invite data journalists. They could learn a lot from other attendees, have a meta story about exactly the topic they’re passionate about, and an inside track on general interest data-driven stories developing from data-driven science in a variety of fields — for example the conference featured a number of sessions on disaster data. Usual CODATA science and policy attendees would probably also learn a lot about how to make their work interesting for data journalists, and thus be able to celebrate rather than whinge when talking about media. A start on that learning, and maybe ideas for people to invite might come from The Data Journalism Handbook (disclaimer: I contributed what I hope is the least relevant chapter in the whole book).
Someone asked how to move forward and David Carlson gave some conceptually simple and very good advice, paraphrased:
Someone also asked about “citizen science”, to which Carlson also had a good answer (added to by Jane Hunter and perhaps others), in sum roughly:
To bring this full circle (and very much aligned with the conference’s theme and Carlson’s first recommendation above) would have been consideration of scientist-as-citizen. Fortunately I had serendipitously titled my “open data workshop” presentation for the next day “Open data policy for scientists as citizens and for citizen science”.
Finally, “data citation” was another major topic of the conference, but semantic web/linked open data not explicitly mentioned much, as observed by someone in the plenary. I tend to agree, but may have missed the most relevant sessions, though they may have been my focus if I was actually working in the field. I did really enjoy happening to sit next to Curt Tilmes at a dinner, and catching up a bit on W3C Provenance (I’ve mentioned briefly before) of which he is a working group member.
…
I got to spend a little time outside the conference. I’d been to Taipei once before, but failed to notice its beautiful setting — surrounded and interspersed with steep and very green hills.
I visited National Palace Museum with Puneet Kishor. I know next to nothing about feng shui, but I was struck by what seemed to be an ultra-favorable setting (and made me think of feng shui, which I never have before in my life, without someone else bringing it up) taking advantage of some of the aforementioned hills. I think the more one knows about Chinese history the more one would get out of the museum, but for someone who loves maps, the map room alone is worth the visit.
It was also fun hanging out a bit with Christopher Adams and Sophie Chiang, catching up with Bob Chao and seeing the booming Mozilla Taiwan offices, and meeting Florence Ko, Lucien Lin, and Rock of Open Source Software Foundry and Emily from Creative Commons Taiwan.
 Finally, thanks to Tyng-Ruey Chuang, one of the main CODATA 2012 local organizers, and instigator of our session and workshop. He is one of the people I most enjoyed working with while at Creative Commons (e.g., a panel from last year) and given some overlapping technology and policy interests, one of the people I could most see working with again.
Finally, thanks to Tyng-Ruey Chuang, one of the main CODATA 2012 local organizers, and instigator of our session and workshop. He is one of the people I most enjoyed working with while at Creative Commons (e.g., a panel from last year) and given some overlapping technology and policy interests, one of the people I could most see working with again.
Brian Proffitt looks for the next $1 billion open source company. This year Red Hat recently surpassed US$1 billion annual revenues (and also $10 billion market capitalization).
One can debate what counts as an “open source company” (presumably something like “[almost] all software developed and distributed is open source”), but Red Hat is relatively uncontroversial; less so than the companies Proffitt lists as possibly next: EnterpriseDB, , and Eucalyptus. I might have included Canonical Ltd among those, but I didn’t look closely for indicators of whether any could reasonably become $1 billion annual revenue companies, or reach an easier $billion milestone, valuation — Proffitt notes that MySQL AB was acquired for approximately $1 billion in 2008.
An even more obvious addition to the watchlist ought be Mozilla, which should have annual revenues exceeding $300 million. Mozilla is least problematic on the “open source” front, though the for-profit corporation is wholly owned by the non-profit Mozilla Foundation, which could lead one to overlook it as a “company”. This also means it won’t have a traditional company valuation (acquisition price or market capitalization), but it’d be clearly over $1 billion.
There’s one other open source organization that, if it pursued huge revenues and were for-profit (both requiring many counterfactuals that may well have destroyed the project; I advocate neither, though I have advocated huge revenues in the past) would be a billion dollar company by valuation and perhaps revenue as well — Wikimedia. I wonder, given that it forgoes huge revenue from advertising, and most people claim to dislike and find little or no utility in online advertising, what we can conclude about the consumer surplus generated by Wikimedia?
As hugely problematic as they are, huge organizations (most obviously governments and corporations) outcompete smaller arrangements in many aspects of human society. If software freedom and the like is important, advocates ought to be rooting for (and criticizing) huge “open source” institutions. And should also be looking for (admittedly difficult) characterizations of consumer surplus and other “billion dollar” metrics in addition to firm revenue and valuation of future profits.